TL;DR: I built an AI pricing agent that consistently performed 30-40% worse
than random pricing, teaching valuable lessons about RL reward engineering
and business applications. Now this is a work in progress and I intend to
experiment different things to see what sticks, and what doesn't.
Introduction
- Goal: Train a reinforcement learning agent to learn optimal pricing strategies for a SaaS product
- Expected: AI outperforms random pricing by 15-30%
- Reality: AI consistently underperformed by 30-40%
Three Iterations of Failure
I attempted three different approaches, each failing in its own instructive way.
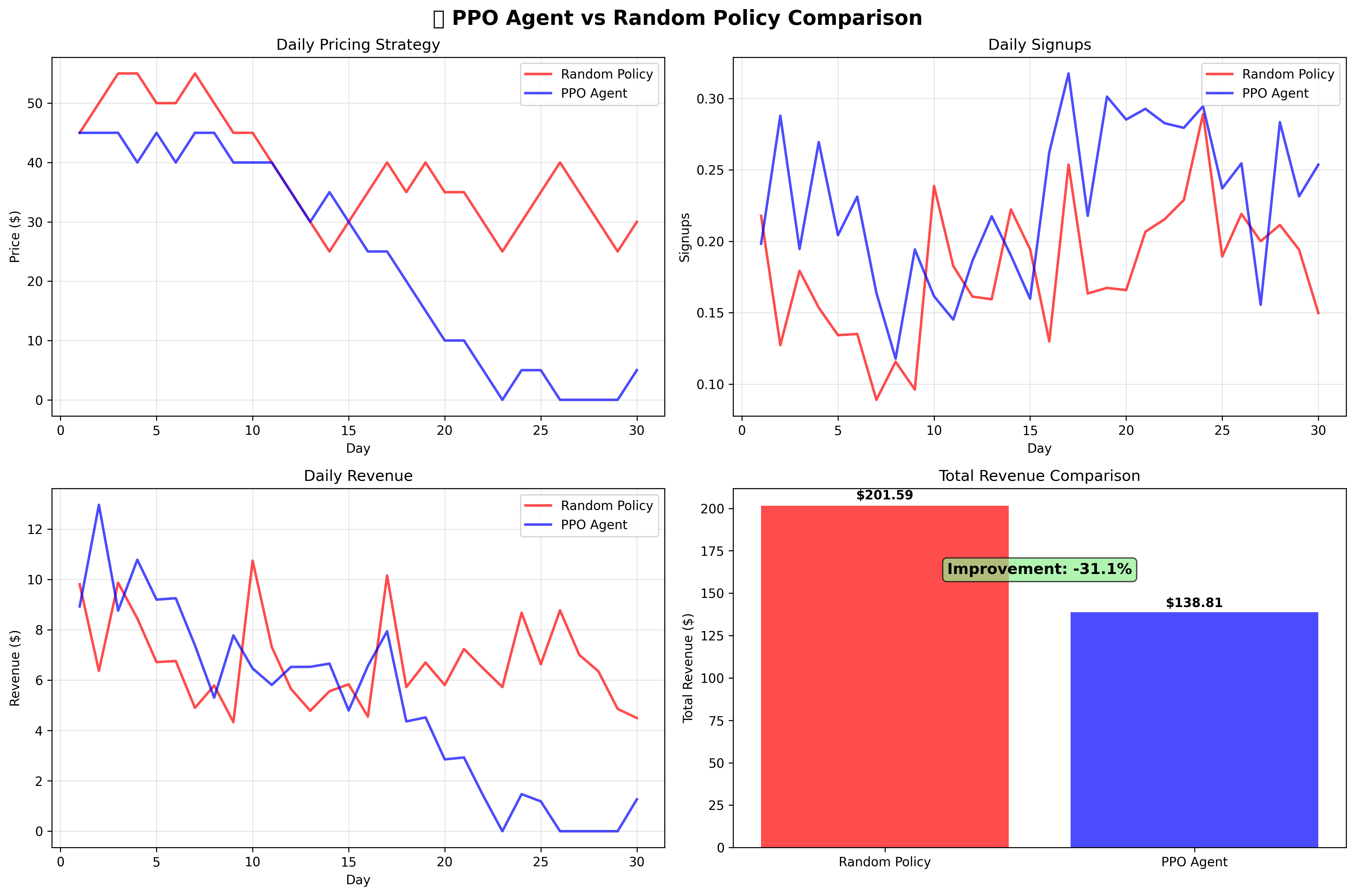
Version 1: Price Crasher Behavior
The agent learned to minimize prices to nearly zero, optimizing for customer acquisition volume rather than revenue maximization.
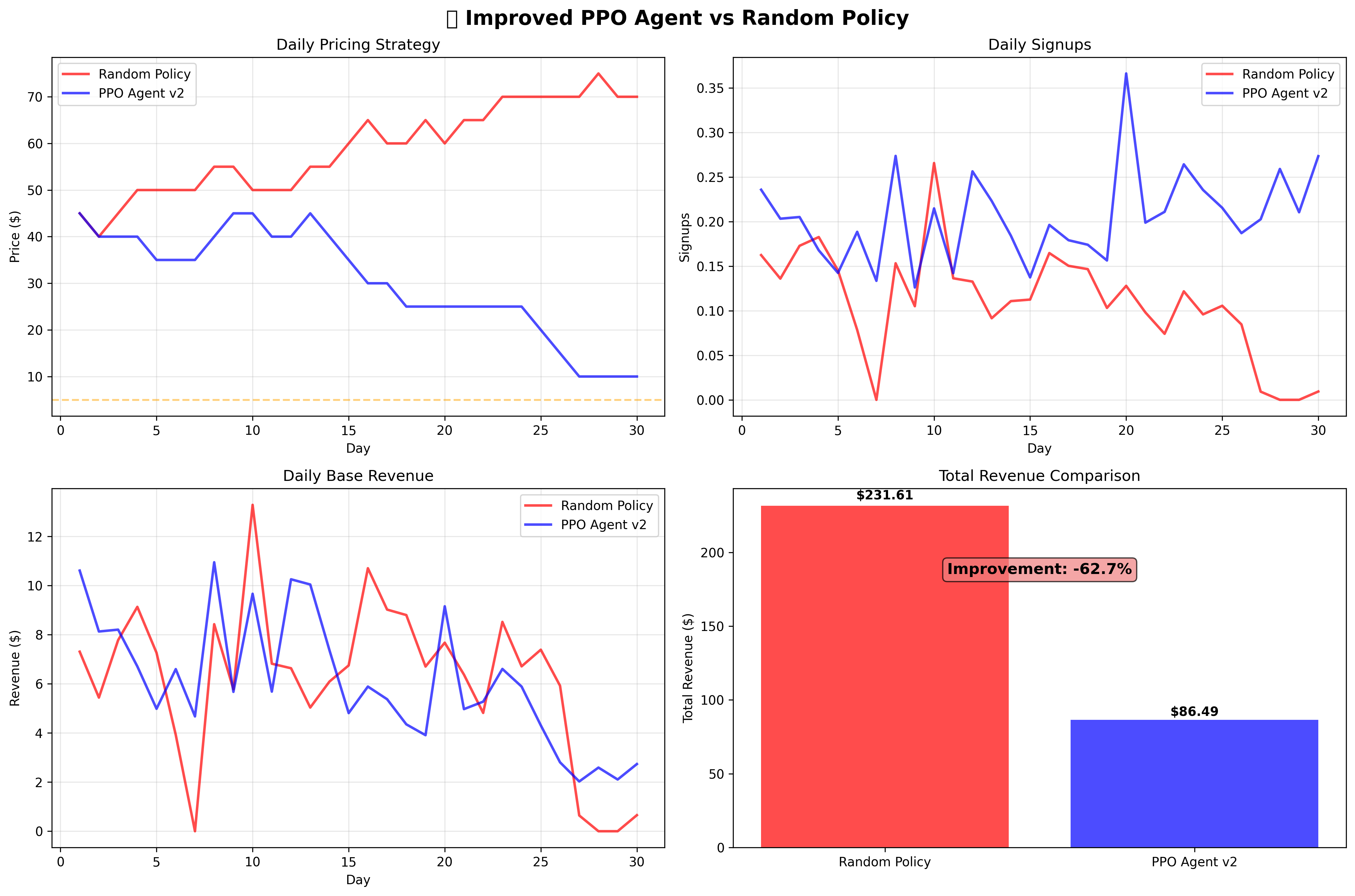
Version 2: Penalty Avoidance Strategy
I added penalties for extreme pricing. The agent learned to avoid penalties while maintaining suboptimal low-price strategies, performing even worse.
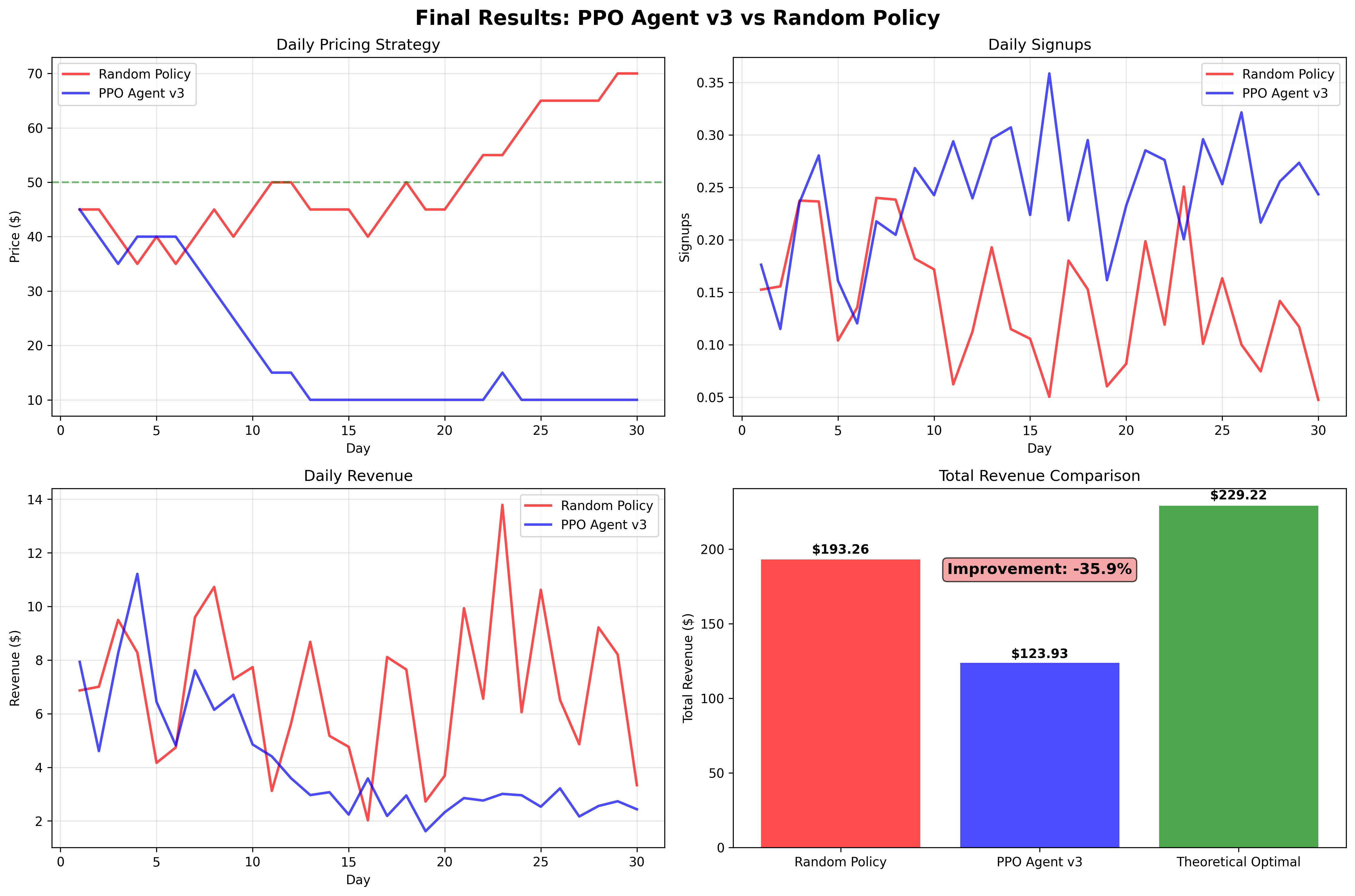
Version 3: Comprehensive Reward Engineering
Despite sophisticated reward shaping with multiple incentive mechanisms, the agent maintained preference for the $10-20 price range.
| Agent Version | Revenue | Strategy | Performance |
|---|---|---|---|
| Random Policy | $193.26 | Varied | Baseline |
| PPO v1 | $138.81 | Price Crashing | -31.1% |
| PPO v2 | $86.49 | Penalty Avoidance | -62.7% |
| PPO v3 | $123.93 | Stubborn Underpricing | -35.9% |
| Theoretical Optimal | $229.22 | Fixed at $50 | +18.6% |
Why This Kept Happening: Core Failure Modes
Local Optimization Traps
The agent consistently converged to local minima, prioritizing customer acquisition metrics over revenue optimization. Despite multiple reward engineering attempts, it never escaped this fundamental misalignment.
Insufficient Exploration
Even with exploration strategies, the agent failed to adequately explore higher-price regions that could yield superior long-term rewards. The immediate positive feedback from customer signups was too compelling.
Temporal Credit Assignment Challenges
The relationship between pricing decisions and revenue outcomes involves complex, non-linear, and delayed feedback signals. The agent demonstrated consistent preference for immediate positive feedback rather than optimizing for long-term objectives.
Lessons Learned
Reward Engineering is Extraordinarily Difficult
Designing effective reward functions for business applications requires extensive domain knowledge and careful consideration of unintended optimization behaviors. Even sophisticated multi-component reward systems can fail spectacularly.
Simple Baselines Can Be Surprisingly Robust
Random pricing with reasonable bounds achieved 84% of theoretical optimal revenue. This highlights how human intuition and domain knowledge often provide more reliable guidance than sophisticated algorithmic optimization in well-understood problem domains.
Algorithm Selection Matters More Than Sophistication
Reinforcement learning may not be optimal for business problems with clear mathematical relationships and well-established optimization techniques. Alternative approaches often provide superior reliability:
- Bayesian optimization for systematic price point exploration
- Multi-armed bandit algorithms for statistical A/B testing
- Classical mathematical optimization for analytical solutions
- Rule-based systems incorporating domain expertise
Evaluation and Baseline Comparison is Critical
The consistent underperformance revealed fundamental limitations that might have been missed without proper baseline comparisons. Sometimes the most educational projects are those that fail to meet initial expectations.
Conclusion
While the reinforcement learning agent never outperformed random pricing, this investigation provided valuable insights into reward engineering complexity, baseline comparison importance, and the limitations of RL in certain business applications. I’m quite curious on how effective random pricing with reasonable constraints can be in such usecases.